
A week after the 512K-routes problem started making waves, we took a look at the global effects to see what impact it had. Spoiler: Not much.
On 12 August there was some buzz among Internet network operators about routing tables hitting a magic 512K boundary. Both BGPMON and Renesys/Dyn have blog entries explaining the situation, including fixes for affected platforms . And whether the exact maximum is 512,000 or 524,288 (2 19 ), the bottom line is that some older routing hardware can by default only hold this many IPv4 routes. We've seen different effects of reaching this limit described: slowing down or crashing because the router switches from fast hardware-based routing to much slower software-based routing, as well as not being able to install any more routes above the maximum. This last case is especially hard to debug, because over time less and less of the Internet will actually be in these routing tables. Without having a default route, that means that less and less of the Internet will actually be reachable through these routers over time.
While that may sound scary it is important to keep some things in mind:
- Only a small portion of Internet routers will be affected by this 512K-problem
- The routers that are affected will be affected at different times, due to local differences in routing policy and routing table size. That said, large spikes in newly announced routes may cause some synchronised failures, like the events around 7:48 UTC on 12 August .
Since we are interested in any Internet-wide effect this may have, we looked at data from the RIPE NCC's Routing Information System (RIS) , which collects routing tables from over 500 peers, including roughly 100 "full feeds". This system provides insight into the control plane of the Internet, in which the Border Gateway Protocol (BGP) is used for routing coordination. The largest BGP-routing feeds we receive in RIS have now crossed the 512K boundary. At midnight on 19 August, the largest feed had 533,917 routes, the 25th largest had 506,934, and the 50th largest had 503,040 routes. This shows there is no single "global routing table", and since each individual router's routing table has its own view of which blocks of addresses to route where, the point at which this table would hit 512K routes is potentially different for every single router.
One interesting signal we can derive from the BGP feeds that RIS collects is the number of autonomous networks, or ASNs, that disappear from the Internet. These autonomous networks are a heterogeneous mix of ISPs, large corporations, universities, etc., and their size ranges from very small to very large. What they all have in common, though, is that they can independently connect to multiple other networks, using BGP for coordination.
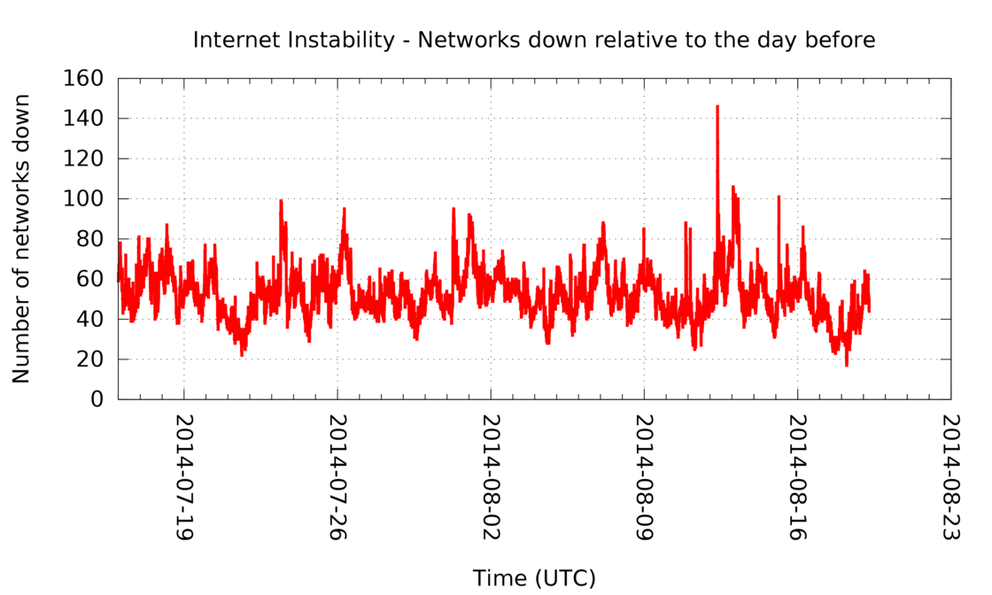
At five-minute intervals we compared the list of ASNs we see with the list of ASNs from exactly a day ago. The result of this is visible in Figure 1 and 2. We recorded the number of ASNs that "went missing" relative to the routing table we saw 24 hours earlier.

Figure 1: The number of networks that are down (2014-07-12 to 2014-08-19)

Figure 2: The number of networks that are down (2014-08-10 to 2014-08-19)
First of all, these figures give you an idea of the dynamics of the Internet. By this definition, at any given time in the last month there are at least 17 ASNs down, and on average there are over 50 ASNs down. For a total of more than 47,000 ASNs, that's not a lot.
Taking a closer look at the networks that are down, they typically only announce a very small chunk of the Internet and connect to relatively few other networks, making them relatively less resilient to failure than better connected networks. This way of looking at the stability of the Internet won't show partial outages of larger networks. The smaller networks are, in a sense, the canaries in the coal mine for the stability of the edge of the Internet. Larger networks will have more routers, so even if some of them go down, it is unlikely that all prefixes will go down because of that. And in normal, day-to-day operations, prefix announcements and withdrawals come and go – any signal in the number of prefixes going down due to 512K is easily drowned out by this day-to-day noise.
In Figure 2, the 12 August event is easily recognisable as a spike of roughly 140 ASNs going down. What's interesting is that we see the peak in missing ASNs appear roughly 15 minutes after the BGP spike at 7:48 UTC . And while we don't know what fraction of ASNs went down because of 512K problems, it definitely stands out from the normal level of ASNs being down. Characterising the ASNs that went missing in more detail, we see 33 Romanian, 32 Russian and 19 US networks being down at 8:10 UTC that day. The largest network, in terms of IPv4 address space announced at that time, is a Finnish network with 67,840 IPv4 addresses in aggregate. A large fraction of the networks that were down announced a single block of 256 IPv4 addresses.
Another spike of downed networks is visible on 15 August at around 03:25 UTC. At this time 101 ASNs were down, the largest being a US Army Information Systems Command ASN, spanning 133,888 IPv4 addresses. Since 55 of the downed networks are Brazilian, there is some locality to this event. There is no single upstream network of these going down, although AS18881 appears to be an upstream for many of the Brazilian networks that were down. AS18881 shows a drop from 2071 to 1801 in announced prefixes around the same time. Again, it is unclear what fraction of networks going down is related to 512K routes, and whether the outages were planned or not.
So one week in from when 512K started making waves, we have seen some synchronised downtime of (mostly smaller) networks. And while local network outages may be a little bit more prevalent compared to before, the Internet certainly didn't go up in flames.
We are looking into ways in which RIPE Atlas can help detect local problems, especially the hard to diagnose failure cases where address space doesn't make it into routing tables anymore.
If you have ideas on how we can make our tools or reporting better, specifically for cases like this, please don't hesitate to comment below.
Comments 2
The comments section is closed for articles published more than a year ago. If you'd like to inform us of any issues, please contact us.
Mike •
I'd be interested in your insights on how flapping was, or still may be, having an impact? I envision something like the digital equivalent of Alzheimers patients playing Marco Polo?! Some announcements not able to be received, creating in some cases conflicting information (routes) about the same ASs. "Here! No, Here!! Nooooo... HERE!!!
Emile Aben •
Around the August 12 07:48 UTC event there was a lot of BGP churn, see for instance https://twitter.com/bgpmon/status/500531013538545664/photo/1 . Afterwards I haven't been able to find a clear signal of this in the noise just yet.